For the last few year at JazzGraphs I’ve depended on the MusicBrainz database to draw data that populates many of the network graphs and other visualizations on the site. It’s an immense dataset that can be downloaded (as I’ve previously done) or accessed via the MusicBrainz API (Application Programming Interface). For upcoming visualizations, I’ve elected to go the API route, but simply as a means to access data, not to use in traditional API fashion. This approach allows for querying the topics I choose – specific artists, genres, recordings, etc. and pull down only the data needed to create a visualization.
Category: jazz
Part 1A: Cataloging My Music
Well, that was fun! Just finished capturing all my vinyl recordings using the dictate functionality in Microsoft Word; what could be better on a cloudy, windy day in the Motor City? This is merely the first step in capturing all the music I have accumulated over the last 25-30 years; unfortunately some old albums from my youth are long gone 🙁
Getz, Parker, Henderson Networks Updated
I’ve added three more jazz artist networks following the same template I used for the initial group I added earlier in the week.
https://jazzgraphs.com/graphs/charlie_parker/
https://jazzgraphs.com/graphs/stan_getz
https://jazzgraphs.com/graphs/joe_henderson
Each of these network graphs show the connections between an artist, his releases, and the songs on each release. The graphs are easy to zoom, pan, and click, with an information panel opening on the left side of the screen. Enjoy!
Shorter, Coltrane, Gordon Networks deployed
After a weekend trying multiple approaches at incorporating images of jazz musicians as backgrounds to their network graphs, I finally hit on a good solution – create icon-like images that display in the upper left corner of the graph background. This allows the network to be easily viewed on multiple devices ranging from phones to widescreen monitors, without interfering with any of the network elements.
Here’s the solution, as shown for the Dexter Gordon network:


Nice and tidy, with an icon-like image created in Powerpoint; the outer circle around the image is colored to match the artist node at the center of the graph for a consistent visual appearance. Even when the sidebar is shown and the graph is zoomed in, this approach works well:


Note that the musician image is combined with the background color and the circle shape in Powerpoint, and is then saved as a picture we can use in our CSS file for the network. Here’s a look at the styling elements for this graph:
#carte {
position: absolute;
background-image: url('../img/Gordon_20230306.png');
background-repeat: no-repeat;
background-size: cover;
left: 0px;
width: 100%;
height: 100%;
}We ensure that the background image is set to cover the entire screen by using the background-size attribute and setting it to ‘cover’. This enables the background to adjust to larger screen sizes seamlessly – no awkward edges to be seen!
From my perspective, this approach solves two issues in a very nice way:
- First, it provides a consistent look & feel to the networks, regardless of which artist we select
- Second, it is very production-friendly; I can use the same background and circle while adding in a new artist picture. This provides a very efficient solution for creating future graph networks
I’ll be adding more permanent links to all of these networks, but for now, here are the initial three:
https://jazzgraphs.com/graphs/dexter_gordon
https://jazzgraphs.com/graphs/wayne_shorter
https://jazzgraphs.com/graphs/john_coltrane
Thats’ it for now – have fun with the networks and thanks for reading!
Refining the Musician Networks, Part 1
I recently posted about the six new saxophonist networks I created using MusicBrainz data and Gephi, and have subsequently created another four, including networks for two of the acknowledged giants of the instrument – Charlie Parker and John Coltrane. However, as I was digging deeper into the data I realized that there are a lot of redundancies in the data due to a couple of grammatical issues. There are two major issues I have now addressed that will make for cleaner networks.
Here’s what these networks currently look like:

I expect to replace these with cleaner, more logical graphs after making this pair of changes. The end result will have fewer nodes and fewer edges crossing each other to connect nodes.
The first change to address is the subtle but important difference between an apostrophe character ( ‘ ) and the similar yet slightly different grave ( ` ) character. Each one is used to represent an apostrophe in the MusicBrainz release.name field, leading to duplicate entries that are actually the same song. For example, ‘Round Midnight versus `Round Midnight. Subtle difference, right? But one that my postgres queries and ultimately Gephi see as two unique songs, cluttering the network graph unnecessarily. So how do we fix this issue in the data?
I first created a new version of the releases table, just in case something went wrong as I tried to make any updates. We now have an empty table with all the same attributes as the original. Step 2 is to populate the new table with a simple SELECT INTO statement:
select * into public.release_new from public.release rThe next step is a bit trickier since it involves an apostrophe character, which postgres treats as quotation marks for other characters. We have to use some additional formatting to convince postgres that we really do want to replace all our ` characters with ‘ characters. Here’s the code I used (there are several ways to do this):
UPDATE
public.release_new
SET
"name" = REPLACE(name,'`',E'\'')
WHERE
"name" > '0'Without going into too much detail, we are telling our query to find all ` characters and replace them with an apostrophe. I recognize this might mess up some cases where there is an actual grave accent on a song name, but we will now have a consistent approach rather than two slightly different characters throwing us off. The goal is to ensure that we recognize a given song as a single node for our graph as much as humanly possible.
We have a second issue to correct for, but this one can be done within our query rather than updating the database. In this case, some songs are listed in upper case in one place, and then as lower case in another. We could force all text to lower case for a match, but that is less than ideal. The same holds true for upper case; we don’t want our graph labels to be all caps. A third solution is to use the INITCAP function in postgres, like this:
select b.id, b.name, b.label, b.type, SUM(b.size)as size
FROM
(SELECT DISTINCT INITCAP(a.id) as id, INITCAP(a.name) as name, INITCAP(a.label) as label, a.type, a.sizeINITCAP forces all first letters to upper case while leaving the other letters as they were. It’s not a perfect solution; apostrophes cause us a problem here too, but it’s perhaps a 99% solution. By correcting the apostrophe format and then using INITCAP, we now have a much cleaner query result for Gephi. As an example, the nodes query for Joe Henderson now returns 269 records, versus the original 285, an improvement of > 5%. This should certainly help clean up our graphs, as it will also reduce the number of edges connecting the nodes.
In part 2 of this series I’ll show the impact these changes have on our network graphs. The beauty of these changes is that I can apply the logic to all future graphs. Thanks for reading, and see you soon.
Six New Saxophonist Networks
Decided to play with the latest version of Gephi by creating a new musician network, and wound up creating six using MusicBrainz data. This was a fun project and will be followed by additional work covering more great jazz musicians. Here’s a quick screenshot of one of the graphs showing the artist, album releases, and songs associated with those releases:
I’ll post the links to each network below and then take a walk through the creation process. Note that the graphs are all interactive, with panning, zooming, edge removal, and other features all available. More on those features later in the post. Here are the links to each network graph:
Note that there are at least two major omissions among saxophonists – Charlie Parker and John Coltrane, and of course some other notable names. I’ll plan to address those omissions in a future post.
To create each of these graphs I followed a simple set of steps and then used the same settings to create graphs with a consistent look & feel. The goal is to have users focus on the structure and content of the network as opposed to having to deal with changing shapes, sizes, and colors. Perhaps I’ll alter this for different instruments – piano or trumpet, for example may have a different color palette. For now, the color palette I have used conveys an appropriately jazzy aura, with the dark background and contrasting pastel-like node colors and subtle gray edges connecting the nodes.
The data for this project is sourced from the impressive MusicBrainz database. Note that MusicBrainz data covers many genres beyond jazz, but for my current purposes the focus is on jazz. I have created a local version of the data using DBeaver for writing and running SQL queries to retrieve data for ingestion by Gephi. DBeaver is a great solution for me – all of my other databases are in MySQL, while the MusicBrainz data is in PostgreSQL format. No problem, as DBeaver can handle both types (as well as many other data formats) with ease.
Here’s an example of the code used for node creation for Sonny Rollins:
SELECT a.*
FROM
((SELECT CONCAT(ac.name, ' (Artist)') AS id, ac.name AS name, ac.name AS label, 'Artist' AS type, 50 AS size
FROM public.artist_credit ac
WHERE ac.id = 21832)
UNION ALL
(SELECT CONCAT(r.name, ' (Release)') AS id, r.name AS name, r.name AS label, 'Release' AS type, COUNT(DISTINCT rl.release) AS size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
WHERE r.artist_credit = 21832
GROUP BY r.name
)
UNION ALL
(SELECT CONCAT(ta.name, ' (Song)') AS id, ta.name AS name, ta.name AS label, 'Song' AS type, COUNT(DISTINCT rl.release)
AS Size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE r.artist_credit = 21832
GROUP BY ta.name
)) a
While the code may appear complex, it’s goal is simple – retrieve all releases and songs for the artist Sonny Rollins, who has the ‘21832’ id. This code creates nodes for the artist (first section), all releases (second section) and all songs (third section). It uses the UNION ALL statement to combine the three sections into a single output file.
We then run similar code to create an edges source file:
SELECT a.*
FROM
((SELECT CONCAT(ac.name, ' (Artist)') AS source, CONCAT(r.name, ' (Release)') AS Target, 'Artist' AS source_type, 'Release' AS target_type
FROM public.artist_credit ac
INNER JOIN public.release r
ON ac.id = r.artist_credit
INNER JOIN public.release_label rl
ON r.id = rl.release
WHERE ac.id = 21832)
UNION ALL
(SELECT CONCAT(r.name, ' (Release)') AS Source, CONCAT(ta.name, ' (Song)') AS Target, 'Release' AS source_type, 'Song' AS target_type
FROM public.release r
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE r.artist_credit = 21832)) a
GROUP BY a.source, a.target, a.source_type, a.target_typeThis output will instruct Gephi to use the artist as a source node and all releases as target nodes (first section) and then to use all releases as source nodes with songs as target nodes. Think of this as a hierarchy of Artist –> Releases –> Songs where individual songs are associated with the release they appeared on. Of course, in jazz, many of the most popular songs will appear connected to multiple releases, ultimately making for a more interesting graph.
Now that we have created the source files, let’s shift to Gephi to see how we use them.
Gephi allows us to pull in spreadsheet files as long as they meet certain criteria. Node files should have a name, label, id, and preferably a size attribute, although this can be created within Gephi based on the data. Edge files must have source and target fields, and ideally a weight value corresponding to the strength of network connections.
Here’s our data after ingestion, starting with the nodes:
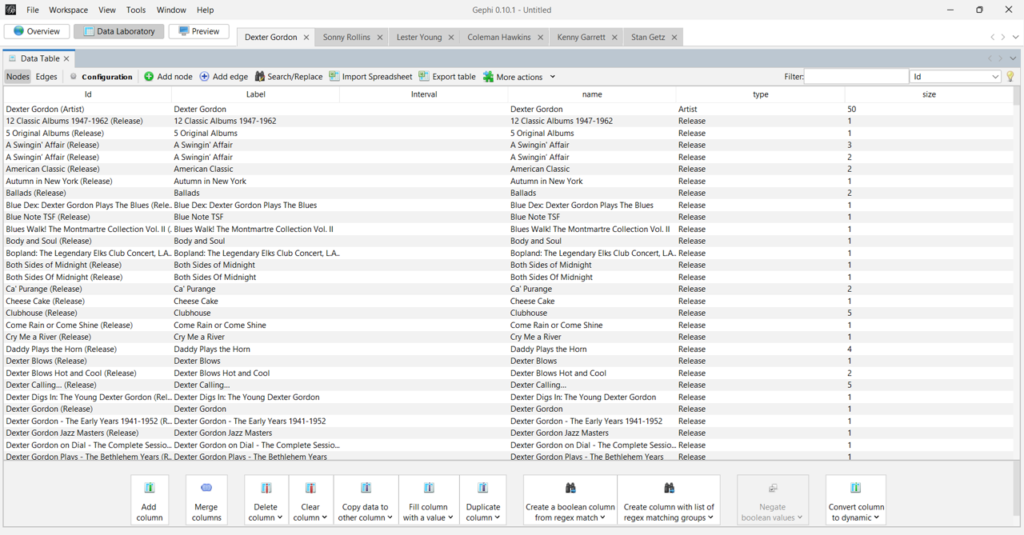
I forget to mention the usefulness of having a ‘type’ column; this will make it simple to set node colors in Gephi. Now the edges file:

You can see the source and target values, which are critical to how the graph will be displayed. Our edge weights are all set to 1 in this network, but frequently we will have varying numbers to indicate stronger versus weaker connections.
Here’s our completed graph in Gephi, after using a number of settings:
- Setting the node colors by type in the Partition tab
- Sizing the nodes in the Ranking tab
- Choosing a layout algorithm – Force Atlas 2 is a popular choice
- Scaling the graph to an appropriate size
- Preventing overlap of nodes
This process can be very iterative, playing with different settings until you are pleased with the results. For graphs like this with hundreds of nodes, different options can be tried very quickly.

The next step is to export the underlying data as a graph file – .gexf is my choice for the web template I use. Here’s a small subset of the Dexter Gordon .gexf file showing the name, type, and size associated with each node.

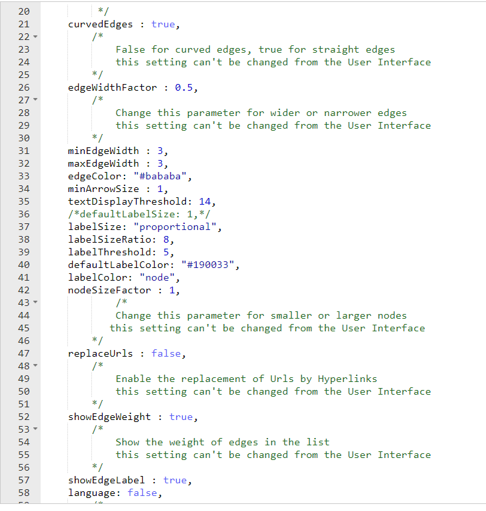
Next, we can update settings in the config.js file; These will adjust the display parameters for the nodes and edges; note that there is also a .css (Cascading Style Sheet) file where many more modifications can be made.
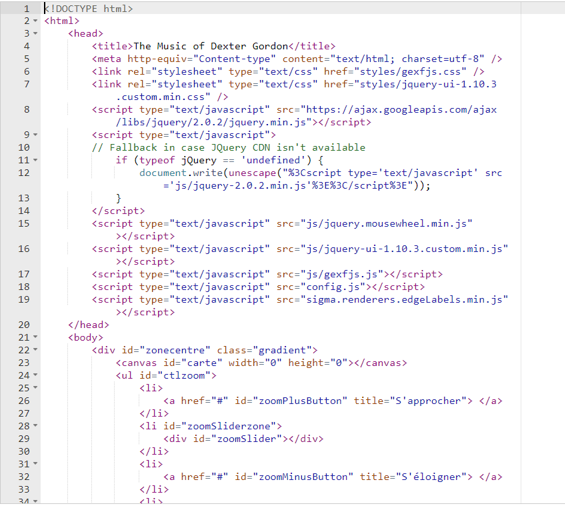
Finally, we have the index.html file that contains links to several scripts as well as the config file. This is where we can also add a title and small bits of information about the graph content.
I’ll be creating additional network graphs using this same end to end approach. The process becomes easier once the code has been tested and validated, and the settings have been standardized in Gephi and the resulting output files; much of the effort will simply involve copying and pasting existing settings. Watch this space for new graphs, and thanks for reading!
Miles Davis Song Plots
In this blog we’re going to use Flourish with more MusicBrainz data to plot the length of Miles Davis songs on a range of vinyl releases. This type of data often suggests the use of a scatter plot with an x-y axis to best visualize the information. For instance, we could place record labels on the x-axis, and the length of each song (in seconds) on the y-axis. However, with record labels being a categorical variable (i.e.- discrete values such as Sony, Columbia, etc.) there are better options for understanding the data versus a true scatter plot.
The first of these is a boxplot, which provides the ability to see the distribution of data (song lengths) by record label. Let’s take a look at this data in Flourish:
Here we have limited the data display to a single label (showing all was quite messy!). Select CBS or Columbia to see labels with many Miles Davis releases. We now see the median length of a recording, as well as the 25th percentile (bottom of the box) and the 75th percentile (top of the box). It’s also easy to see individual songs that lie below or above the typical range; in statistical terms, these are called outliers. On our plot, they represent songs that are either much shorter than normal (below the extended line) or longer than normal (above the extended line).
This is all useful information, but presents some limitations. Boxplots are very good at doing the aggregations for us while obscuring the individual data values, especially values that lie inside the box. To improve our ability to see those values we turn to a violin plot, which excels at showing the shape of a distribution, rather than the fixed shape provided by the boxplot. We have also combined a beeswarm plot with the violin plot so we can see every individual value:
Again, select CBS or Columbia to view a label with many releases/songs to understand why we elected to use this approach. Hover over individual points to learn more about an individual song – it’s length, release, artist, label, and song title. For me, this approach is best if I’m trying to explore the data; the boxplot is great when I’m interested in overall patterns. Both are powerful tools suited to their individual strengths.
I’ll be using Flourish to interrogate the MusicBrainz data further in future posts, but that’s it for now. Thanks for reading!
Miles Davis Sunburst Visualization
With the Christmas holiday chaos (somewhat literally this year) in the rearview, I’ve been playing a bit with the MusicBrainz data and the Flourish visualization library. First up was using some repurposed code to visualize Miles Davis recordings. I thought a sunburst diagram might be an interesting way to show album releases and the songs on each release. Turns out it wasn’t quite as simple as I thought…it never is!
After multiple query tweaks and iterations, I’ve got something fun and interesting. Miles produced so much music, with much of it re-released in multiple formats (think vinyl vs. cd) and in various collections, factors that wound up influencing my query and chart logic. As is the case for many jazz artists, multiple labels are an issue, so why not create a filter to view releases for each label (Columbia, Blue Note, etc.)? And many songs turn up on multiple releases (studio, live, collections), so we need to account for that as well.
So my thought with using a sunburst was to group songs and releases together, and allow filtering by label. Mind you, it took multiple attempts to get the data in the best format, but we eventually wound up with something workable to feed the sunburst chart.
If you aren’t familiar with the sunburst chart, here’s a quick primer. The goal of a sunburst chart is to display hierarchical information in a circular layout with 2 or 3 levels (typically). The outer layer has more surface area to work with, and successive inner layers each have less visual space to use. For this reason, I wound up using individual songs in the outermost layer, with their respective albums as the inner layer. With an average of perhaps 5-10 songs per album, this takes advantage of the sunburst hierarchy framework.
Here’s what the code eventually became, after multiple iterations:
SELECT distinct ac.name AS artist, l.label_code, l.name AS label_name, r.name AS release, mf.name AS format, t.name AS id, t.name AS label, t.name AS name,
r.name AS recording,
CASE WHEN t.length < 180000 THEN ‘< 3 Minutes’ WHEN t.length < 300000 THEN ‘3-5 Minutes’ WHEN t.length < 420000 THEN ‘5-7 Minutes’ WHEN t.length < 600000 THEN ‘7-10 Minutes’ WHEN t.length > 600000 THEN ’10+ Minutes’
ELSE ‘No Length’ END category
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.recording re
ON t.recording = re.id
WHERE r.artist_credit = 1954
and mf.name = ’12” Vinyl’
ORDER BY l.name, r.name
What we’re doing here, in a nutshell, is retrieving all the information for Miles Davis’ 12″ vinyl releases; many of these recordings were eventually released on CD, so we’re attempting to avoid duplication here. The ‘r.artist_credit = 1954’ line refers to Miles Davis and his MusicBrainz artist ID, while the medium_format name field is set to grab just 12″ vinyl releases.
Enough of the technical details – let’s view some results:
Here’s a look at the dropdown filter we created using labels:

Note that we ordered our query by both label name and release name; this translates to an alpha sorted dropdown on labels, making it much more intuitive to select a specific label. We can choose to display all labels, but that gets rather messy for an artist like Miles who recorded for or was re-released by many companies. Let’s filter it down to Columbia, a major label who Miles recorded for many times:


The inner circle displays individual releases, of which there are many, while the outer ring displays the songs on each release. The Flourish sunburst charts are interactive, but it’s a challenge to see what’s going on in our static image. Let’s move to the Blue Note label, a major force in jazz, but one where Miles was not a major player:

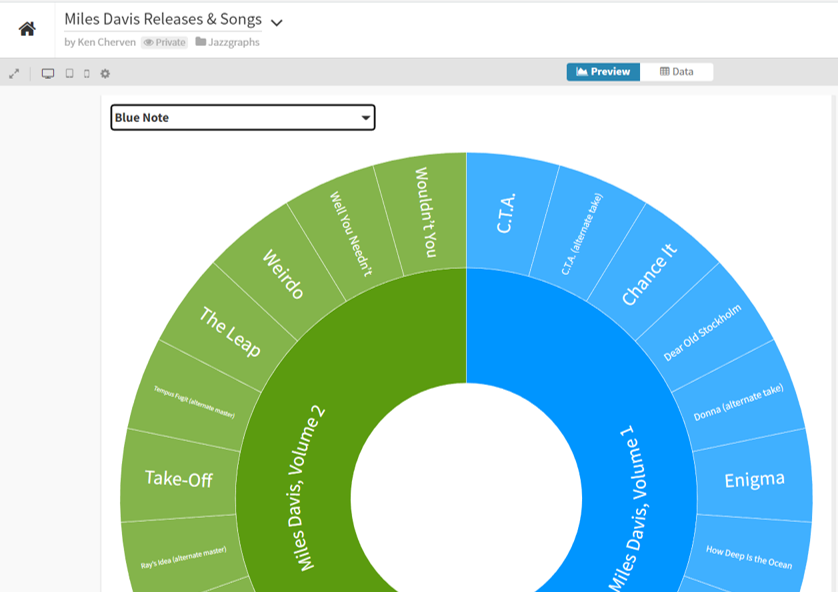
Now we can see the layout, with album releases surrounded by individual songs. We can go a step further by clicking on the Miles Davis, Volume 1 layer, which reveals the following:


Now we are focused strictly on that release and can easily view the songs on that album. Hope you get the general idea for how the sunburst charts work. Now have a go at it yourself with the live version:
I’ll have more of these to come, as it feels like a great way to capture a lot of information in a fun, interactive layout. See you soon, and thanks for reading!
Mapping Venues with Flourish
I recently shared some venue maps created in Carto using MusicBrainz data where we can see all the musical venues (with lat/lng coordinates) listed in the database. Now that I am exploring Flourish as a visualization tool, it is time to test the mapping capabilities to see if it provides a viable alternative for geographic visualization.
As with the Carto map, the first step is to retrieve the data with a query from my local MusicBrainz database:
select p.”name” , p.address , p.coordinates , split_part(trim(p.coordinates ::text, ‘()’), ‘,’, 1)::float AS lat,
split_part(trim(p.coordinates ::text, ‘()’), ‘,’, 2)::float AS lng,
pt.”name” as type, ar.name as locale
from place p
inner join place_type pt
on p.”type” = pt.id
inner join area ar
on p.id = ar.id
where p.coordinates is not null
The results are exported to a .csv file for ingestion by the Flourish map template. In this case we are using a point map to display venues using the latitude (lat) and longitude (lng) data we just created. Before uploading our data, we can see that Flourish provides an easy to use template populated with sample data, allowing us to see the data format we need to deliver:
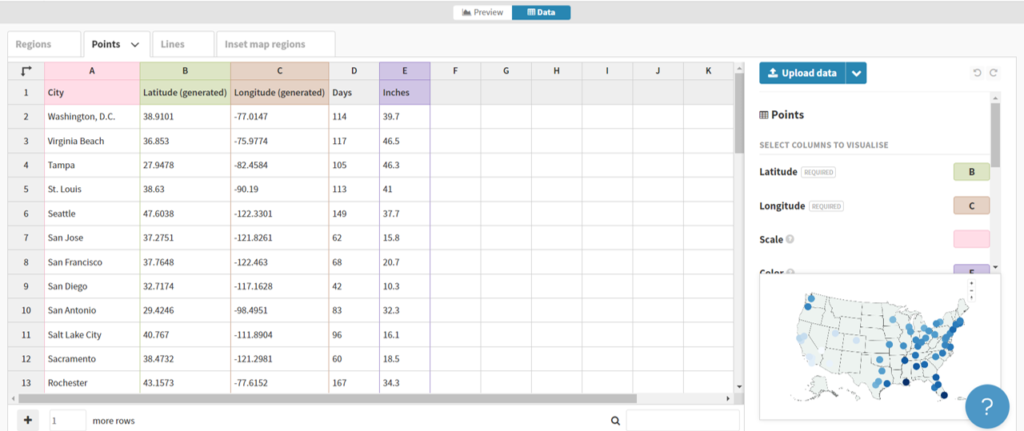
Here we can see a name field (City) and latitude and longitude fields for positioning points on a map. Other attributes provide data that might be used for sizing, coloring, or context.
In our case, we can upload our venues .csv file in this general format, and then tell Flourish which columns to use. Here’s what our data looks like after uploading:

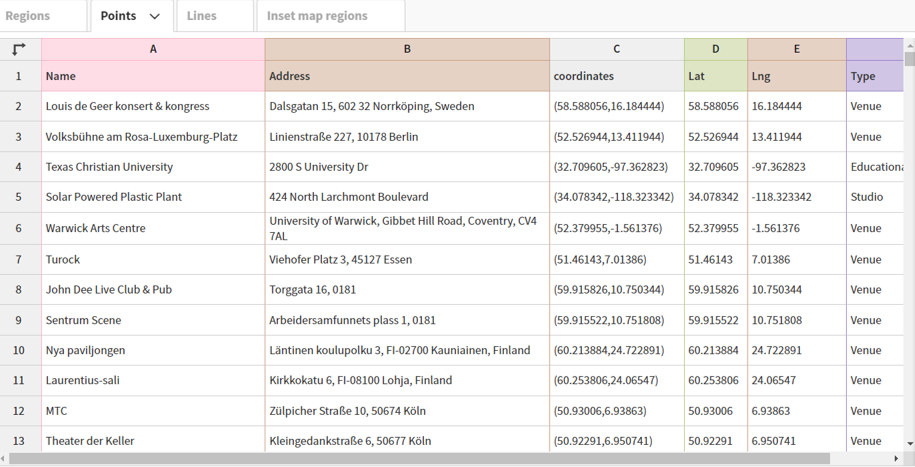
Now that the data has been uploaded we can specify which columns to use. Rather than using column names (Name, Address, etc.), Flourish works off the actual column locations (A, B, C, etc.). These are the values we need to input in the options tab. We can use A, B, and F for describing the data with labels and/or popups, use D for latitude and E for longitude, and switch from the Date to the Preview pane.
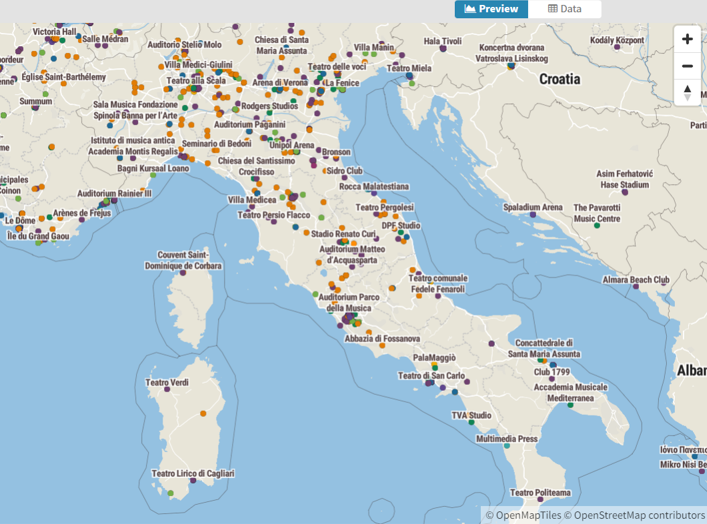
When we complete that task, Flourish gives us an attractive map, with many templates to choose from, and dozens of options for styling the map and surrounding area:

Here’s a quick view of the many available categories for styling your map:
We’ll skip the details for now, but it is obvious that we could do an amazing number of things to customize our map.
To answer my earlier question, it appears that Flourish will be more than capable for mapping a variety of data, and I’m looking forward to testing it with much larger data sets. See you soon, and thanks for reading!
Music Venues – Interactive Maps
As a follow-up to my last post on mapping music venues using the great MusicBrainz database, I am adding interactive versions of the maps for you to explore. First up is the cluster map showing aggregations of venues across the globe. Scroll in and out to view more or less detail:
The second map view uses a categorical approach, coloring each venue by it’s specific type (arena, stadium, etc.) and provides additional information when a venue is selected. As you scroll in the specific venues become more visible:
Have fun exploring, and watch for new maps coming soon!
