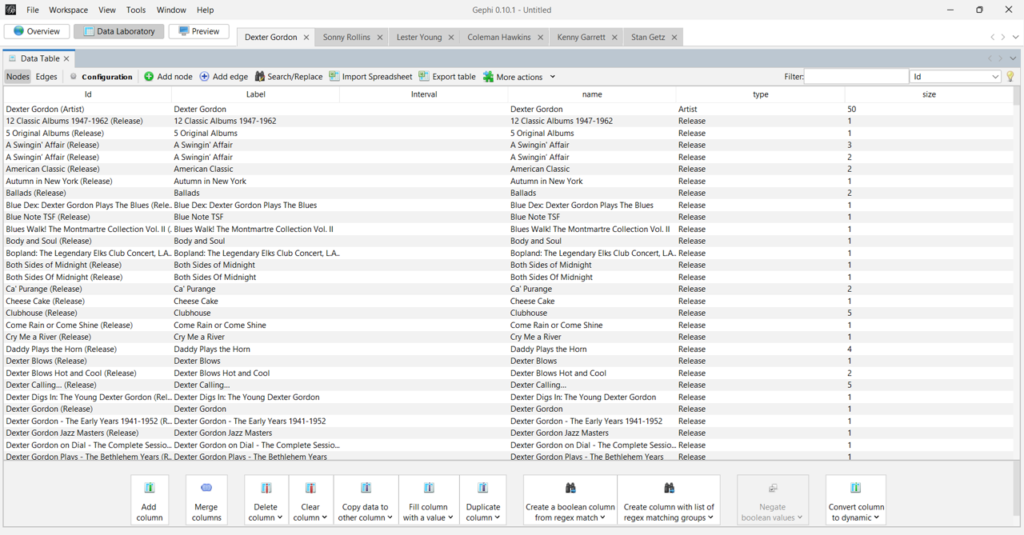
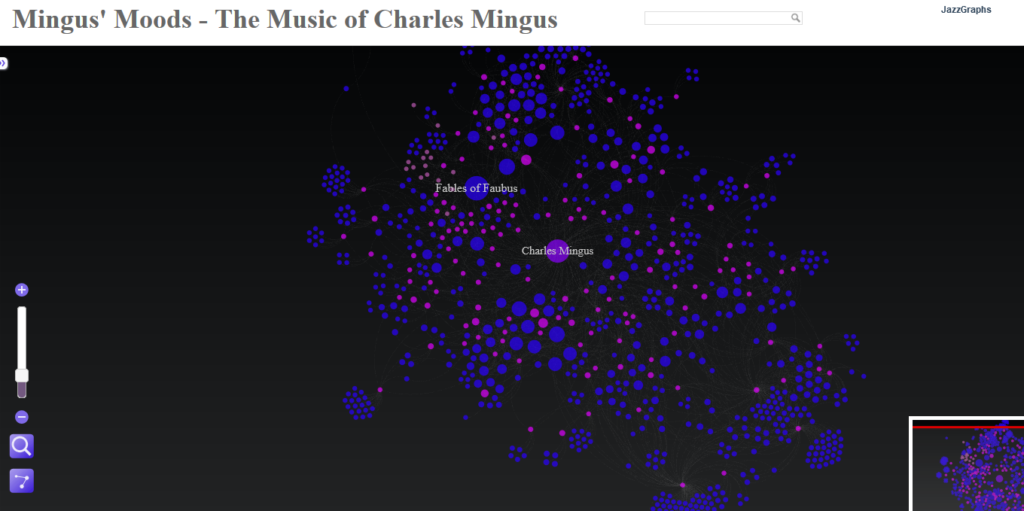
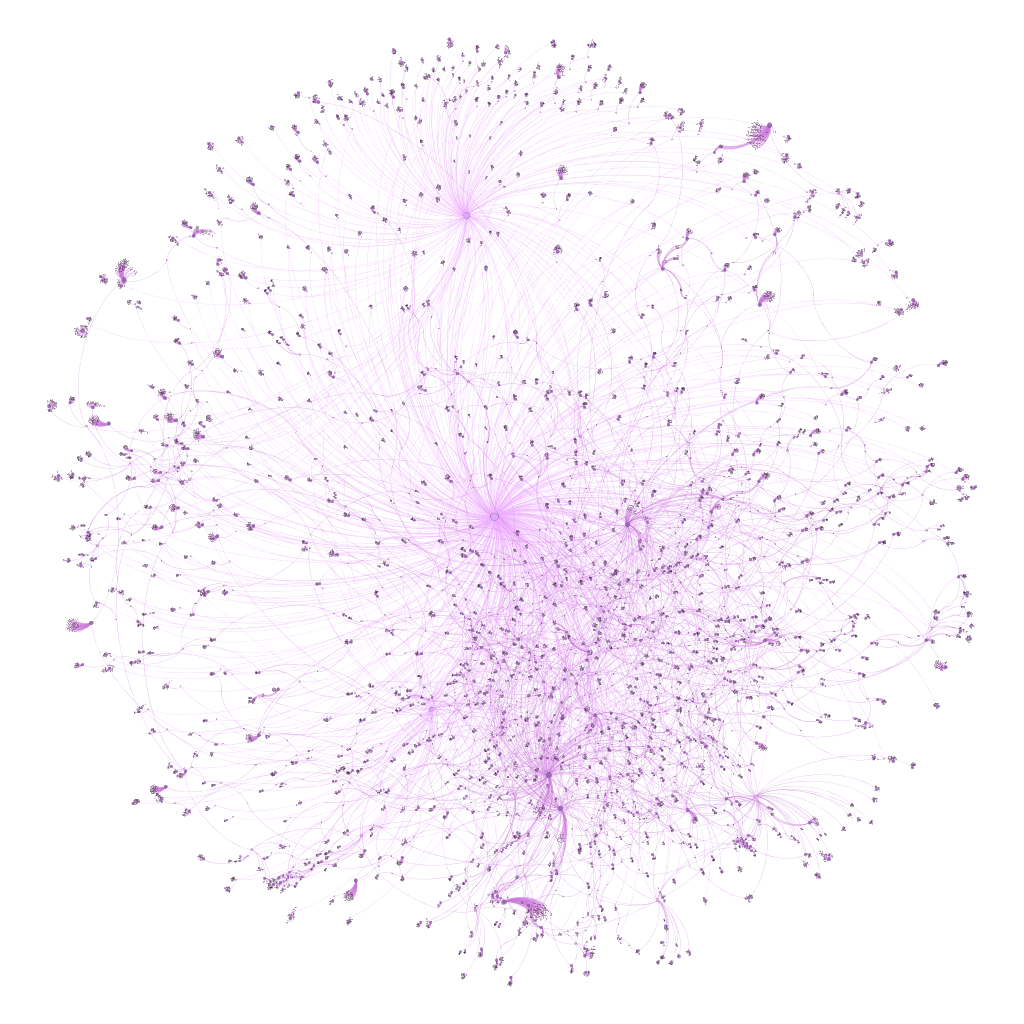
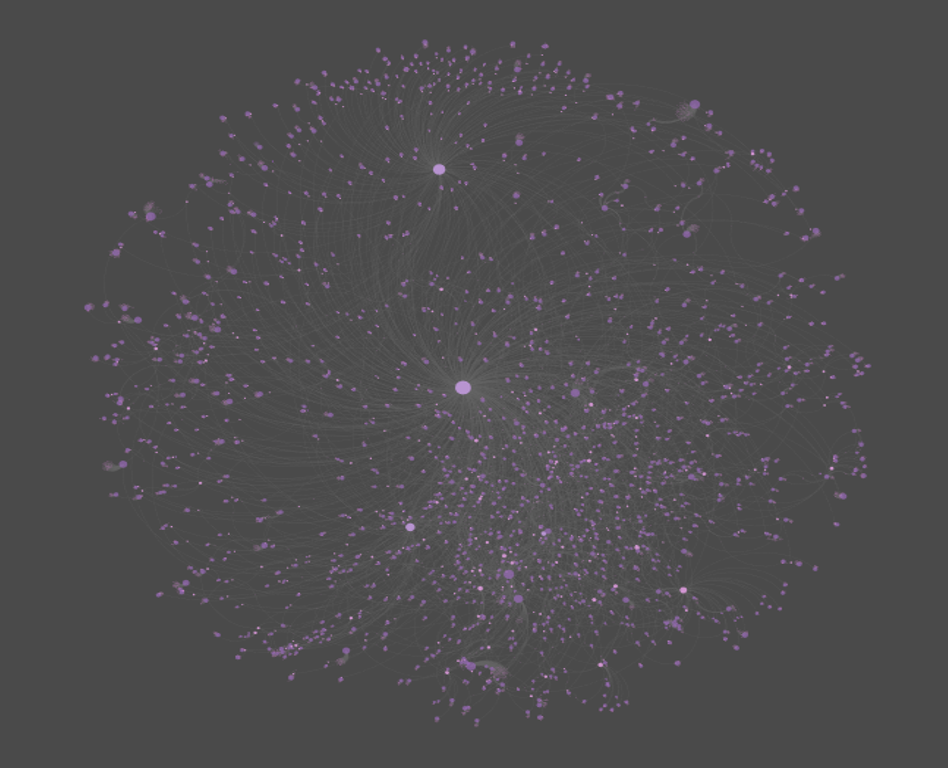
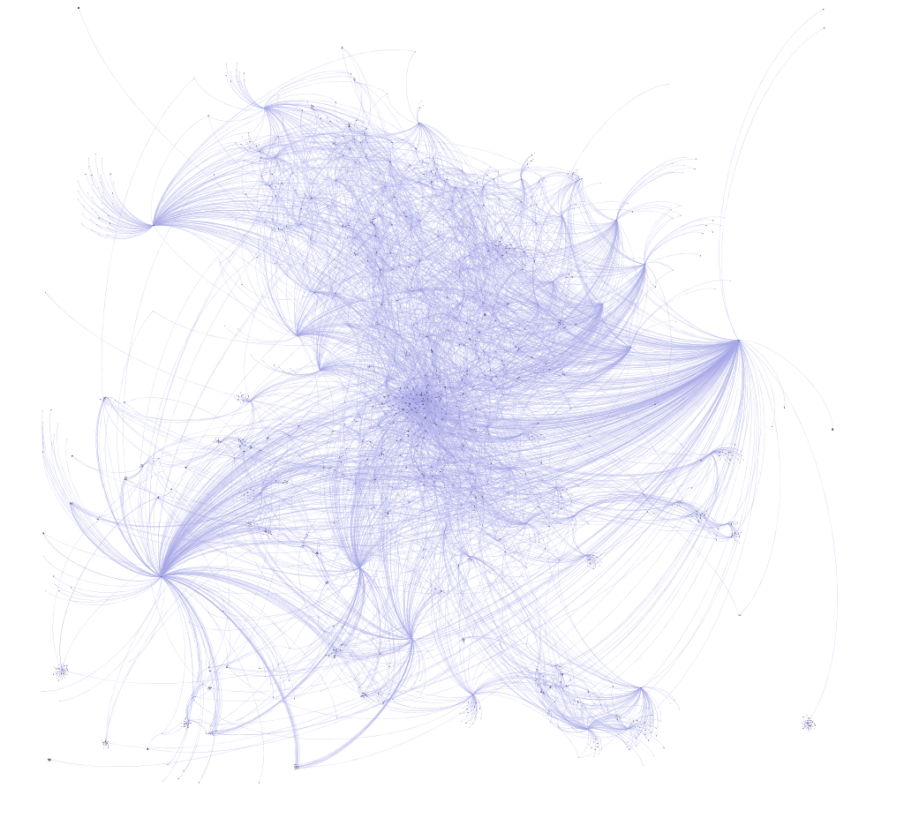
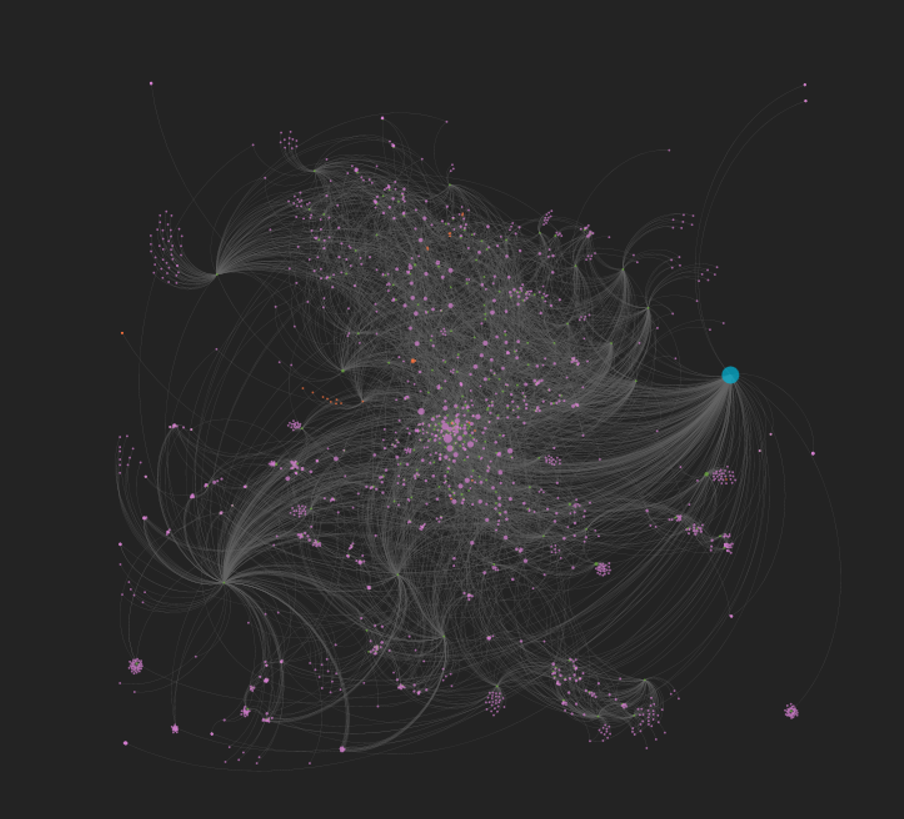
I recently posted about the six new saxophonist networks I created using MusicBrainz data and Gephi, and have subsequently created another four, including networks for two of the acknowledged giants of the instrument – Charlie Parker and John Coltrane. However, as I was digging deeper into the data I realized that there are a lot of redundancies in the data due to a couple of grammatical issues. There are two major issues I have now addressed that will make for cleaner networks.
Here’s what these networks currently look like:

I expect to replace these with cleaner, more logical graphs after making this pair of changes. The end result will have fewer nodes and fewer edges crossing each other to connect nodes.
The first change to address is the subtle but important difference between an apostrophe character ( ‘ ) and the similar yet slightly different grave ( ` ) character. Each one is used to represent an apostrophe in the MusicBrainz release.name field, leading to duplicate entries that are actually the same song. For example, ‘Round Midnight versus `Round Midnight. Subtle difference, right? But one that my postgres queries and ultimately Gephi see as two unique songs, cluttering the network graph unnecessarily. So how do we fix this issue in the data?
I first created a new version of the releases table, just in case something went wrong as I tried to make any updates. We now have an empty table with all the same attributes as the original. Step 2 is to populate the new table with a simple SELECT INTO statement:
select * into public.release_new from public.release rThe next step is a bit trickier since it involves an apostrophe character, which postgres treats as quotation marks for other characters. We have to use some additional formatting to convince postgres that we really do want to replace all our ` characters with ‘ characters. Here’s the code I used (there are several ways to do this):
UPDATE
public.release_new
SET
"name" = REPLACE(name,'`',E'\'')
WHERE
"name" > '0'Without going into too much detail, we are telling our query to find all ` characters and replace them with an apostrophe. I recognize this might mess up some cases where there is an actual grave accent on a song name, but we will now have a consistent approach rather than two slightly different characters throwing us off. The goal is to ensure that we recognize a given song as a single node for our graph as much as humanly possible.
We have a second issue to correct for, but this one can be done within our query rather than updating the database. In this case, some songs are listed in upper case in one place, and then as lower case in another. We could force all text to lower case for a match, but that is less than ideal. The same holds true for upper case; we don’t want our graph labels to be all caps. A third solution is to use the INITCAP function in postgres, like this:
select b.id, b.name, b.label, b.type, SUM(b.size)as size
FROM
(SELECT DISTINCT INITCAP(a.id) as id, INITCAP(a.name) as name, INITCAP(a.label) as label, a.type, a.sizeINITCAP forces all first letters to upper case while leaving the other letters as they were. It’s not a perfect solution; apostrophes cause us a problem here too, but it’s perhaps a 99% solution. By correcting the apostrophe format and then using INITCAP, we now have a much cleaner query result for Gephi. As an example, the nodes query for Joe Henderson now returns 269 records, versus the original 285, an improvement of > 5%. This should certainly help clean up our graphs, as it will also reduce the number of edges connecting the nodes.
In part 2 of this series I’ll show the impact these changes have on our network graphs. The beauty of these changes is that I can apply the logic to all future graphs. Thanks for reading, and see you soon.