One of the great strengths of the MusicBrainz database is that we can build networks using not only artists, but also record labels, or even individual songs. In this post, we’re going to explore an example (per a reader suggestion) using the ECM label and its variants. ECM is known for producing high quality recordings from an array of both jazz and classical artists. Keith Jarrett, Charles Lloyd, and Gary Burton are among some of the better known artists with multiple ECM recordings.
In contrast to our Miles Davis network, where the focus was on the artist, we now wish to see the labels (ECM) as hubs within the network. We’ll take a similar approach to constructing the node and edges files, although we now are going to create a multi-modal structure with 4 layers: Label –> Artist –> Release –> Songs. Using PostgreSQL, we can pull this data quite easily from the MusicBrainz database. Let’s start with the nodes logic:
SELECT a.*
FROM
((SELECT CONCAT(l.name, ‘ (Label)’) AS id, l.name AS name, l.name AS label, ‘Label’ AS type, 30 AS size
FROM label l
WHERE l.id IN(46800,1884,106711,123517))
UNION ALL
(SELECT CONCAT(ac.name, ‘ (Artist)’) AS id, ac.name AS name, ac.name AS label, ‘Artist’ AS type, 10 AS size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
WHERE l.id IN(46800,1884,106711,123517))
UNION ALL
(SELECT CONCAT(r.name, ‘ (Release)’) AS id, r.name AS name, r.name AS label, ‘Release’ AS type, COUNT(DISTINCT rl.release) AS size
FROM public.release r
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
WHERE l.id IN(46800,1884,106711,123517)
GROUP BY r.name
)
UNION ALL
(SELECT CONCAT(ta.name, ‘ (Song)’) AS id, ta.name AS name, ta.name AS label, ‘Song’ AS type, COUNT(DISTINCT rl.release)
AS Size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE l.id IN(46800,1884,106711,123517)
GROUP BY ta.name
)) a
The four sections of code are united by one common attribute – the four record label identifiers associated with ECM. Section 1 creates nodes for the record labels, section 2 the recording artists, section 3 the releases, and section 4 the songs on each release. This should give us a very interesting network, although it will not have the same level of cross-pollination as the earlier Miles Davis network, as the songs are being associated with specific releases.
Creating the edges is quite similar, albeit requiring just three sections of code:
SELECT a.*
FROM
((SELECT CONCAT(l.name, ‘ (Label)’) AS source, CONCAT(ac.name, ‘ (Artist)’) AS Target, ‘Label’ AS source_type, ‘Artist’ AS target_type
FROM public.label l
INNER JOIN public.release_label rl
ON l.id = rl.label
INNER JOIN public.release r
ON rl.release = r.id
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
WHERE l.id IN(46800,1884,106711,123517))
UNION ALL
(SELECT CONCAT(ac.name, ‘ (Artist)’) AS Source, CONCAT(r.name, ‘ (Release)’) AS Target, ‘Artist’ AS source_type, ‘Release’ AS target_type
FROM public.release r
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.label l
ON l.id = rl.label
WHERE l.id IN(46800,1884,106711,123517))
UNION ALL
(SELECT CONCAT(r.name, ‘ (Release)’) AS Source, CONCAT(ta.name, ‘ (Song)’) AS Target, ‘Release’ AS source_type, ‘Song’ AS target_type
FROM public.release r
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.label l
ON l.id = rl.label
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE l.id IN(46800,1884,106711,123517))
) a
GROUP BY a.source, a.target, a.source_type, a.target_type
Here we are simply connecting labels to artists, artists to releases, and releases to songs. Both the node and edge results are saved to .csv files for use in Gephi.
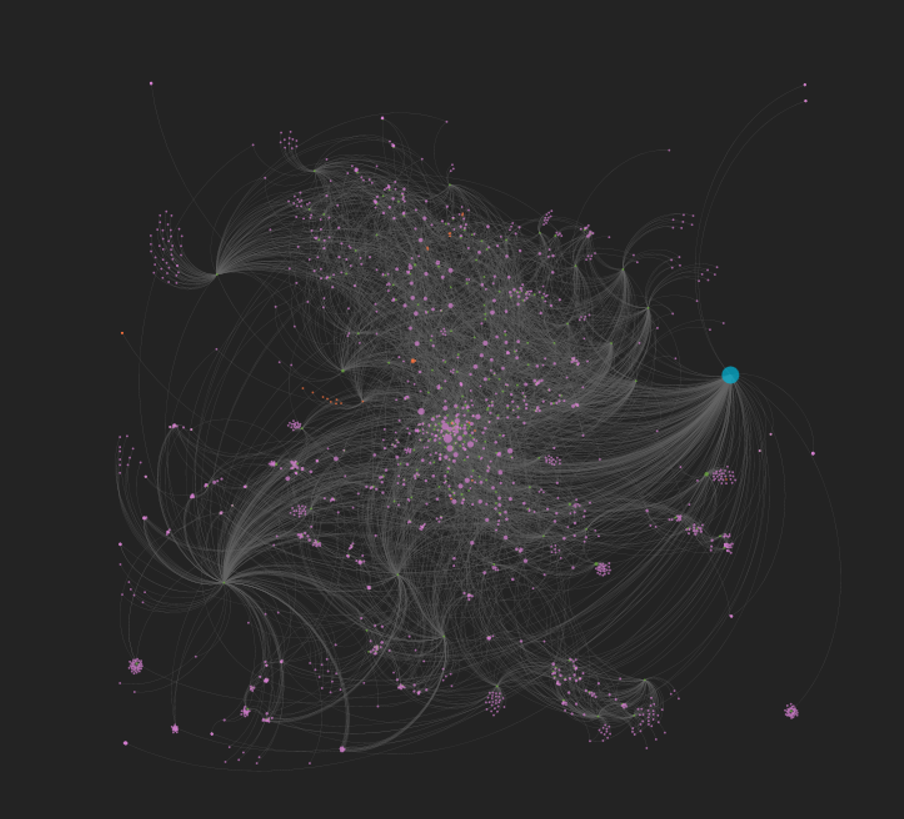
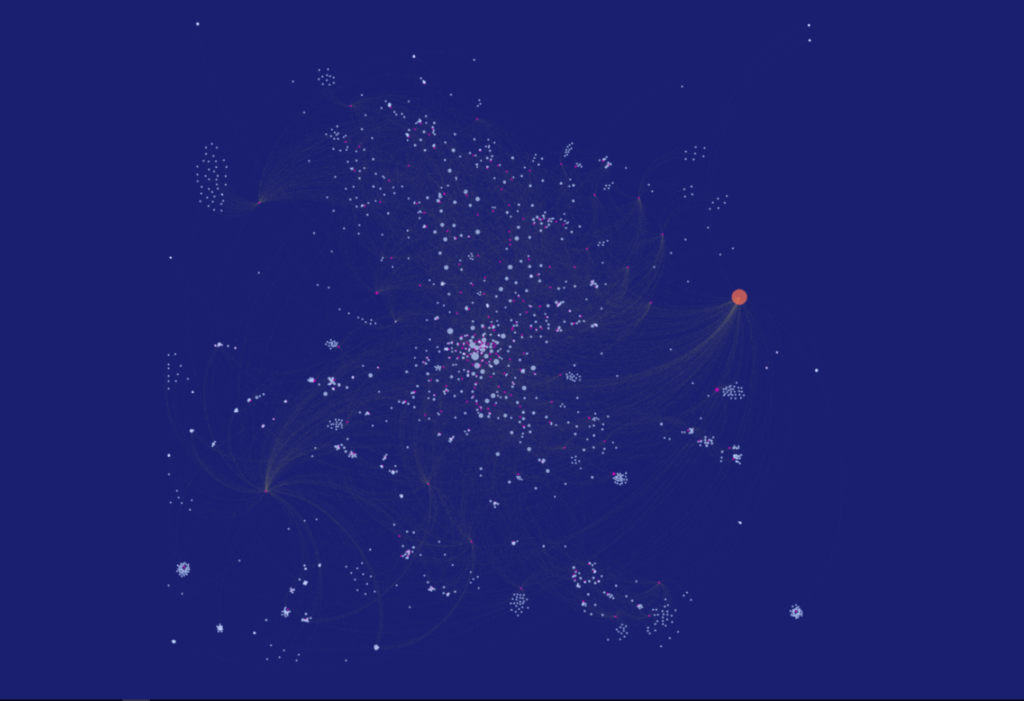
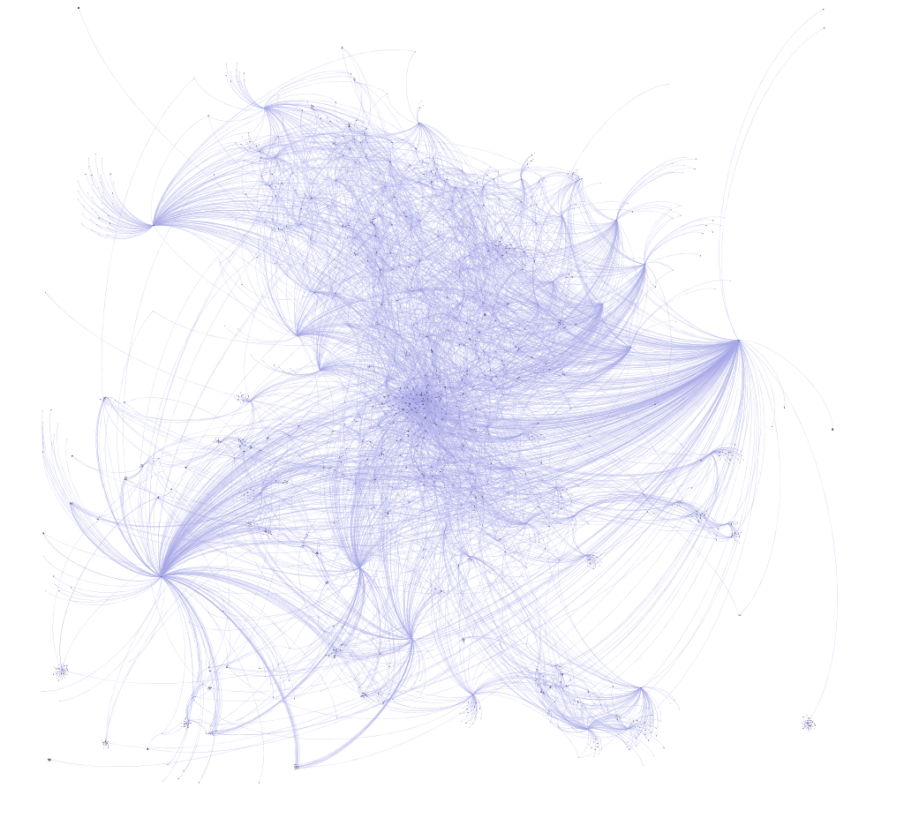
Once the data was in Gephi, I spent parts of a few days testing layouts, spacing, colors, sizing, and so on, before settling for the moment on using the popular Force Atlas 2 algorithm. I find it useful to start the process using the rapid (and less precise) OpenOrd algorithm whenever working with a fairly complex or large dataset. Then, once the basic network structure is revealed, we can move on to Yifan Hu, Force Atlas, or any of the more precise methods.
For the (for now) final version, I elected to size the nodes based on the number of outbound degrees, which will place more visual emphasis on the record labels and releases, respectively. Artists with multiple releases will also be represented by slightly larger nodes. So here are two versions, the first in Gephi:
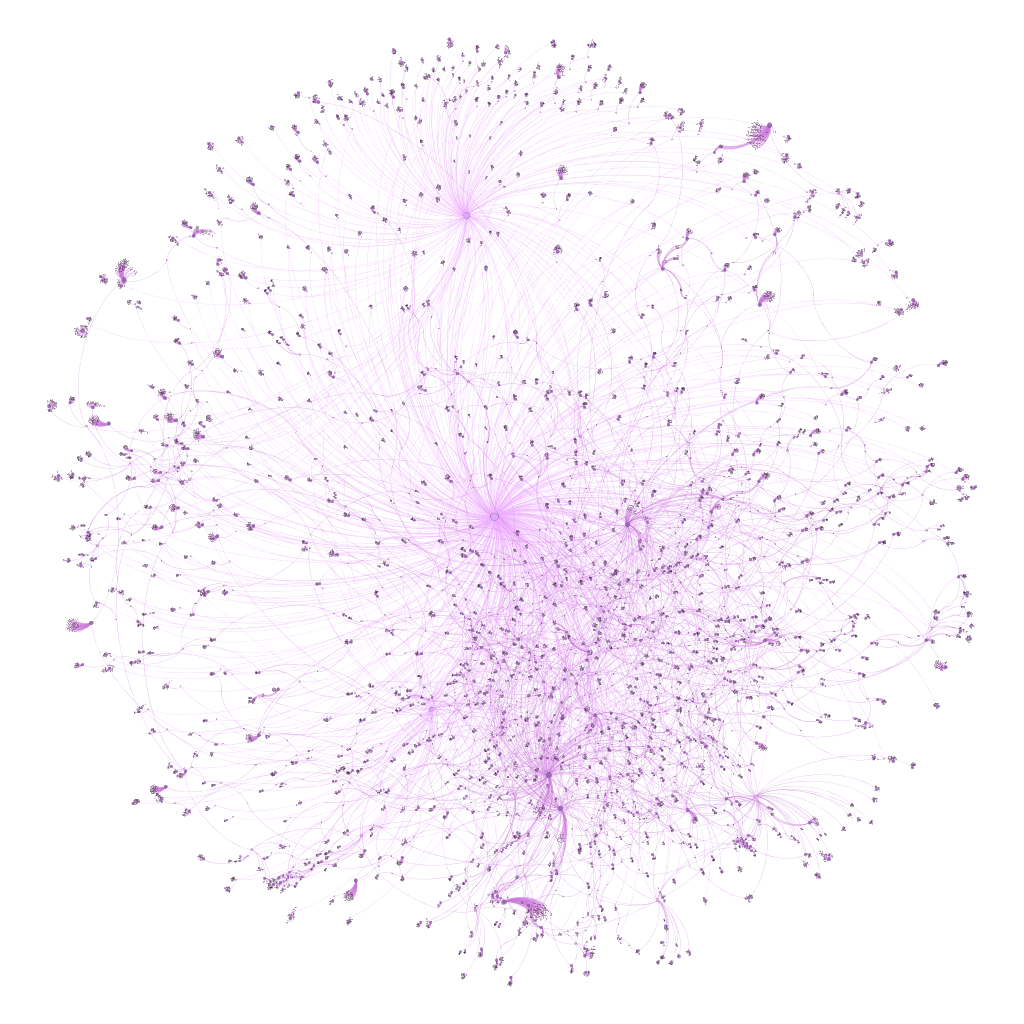
The second version is from the web, after tweaking settings in sigma.js:
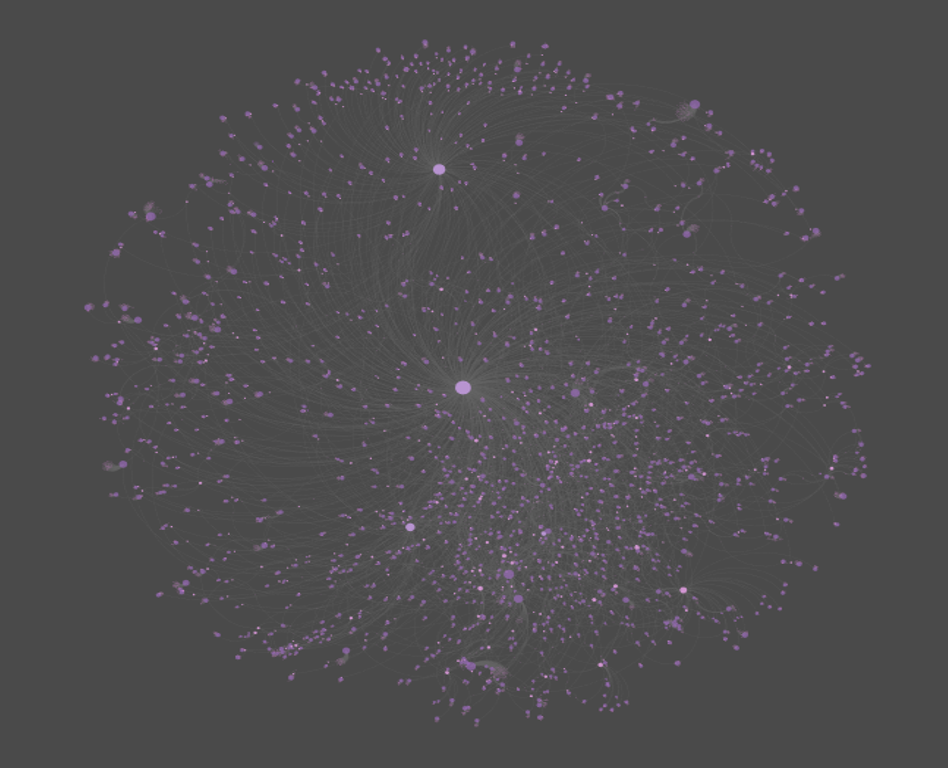
To interact with the network, click here. Thanks for reading!