After a 4-year(!) absence, I’m trying to get back in the groove with the Jazzgraphs site. The first step is to update the data tables behind the scenes, using data from the MusicBrainz project, a sort of Wikipedia for music information. The potential is enormous, but involves some effort on my end to get things rolling again.
MusicBrainz provides an amazing array of data covering artists, recordings, labels, etc. that can be leveraged for some fun visualizations. For now, I’m in the midst of the data wrangling stage, updating each table with the freshest data available so I can stay up to date. BTW, the data extends well beyond jazz, so get ready for some visualizations that extend the boundaries a bit.
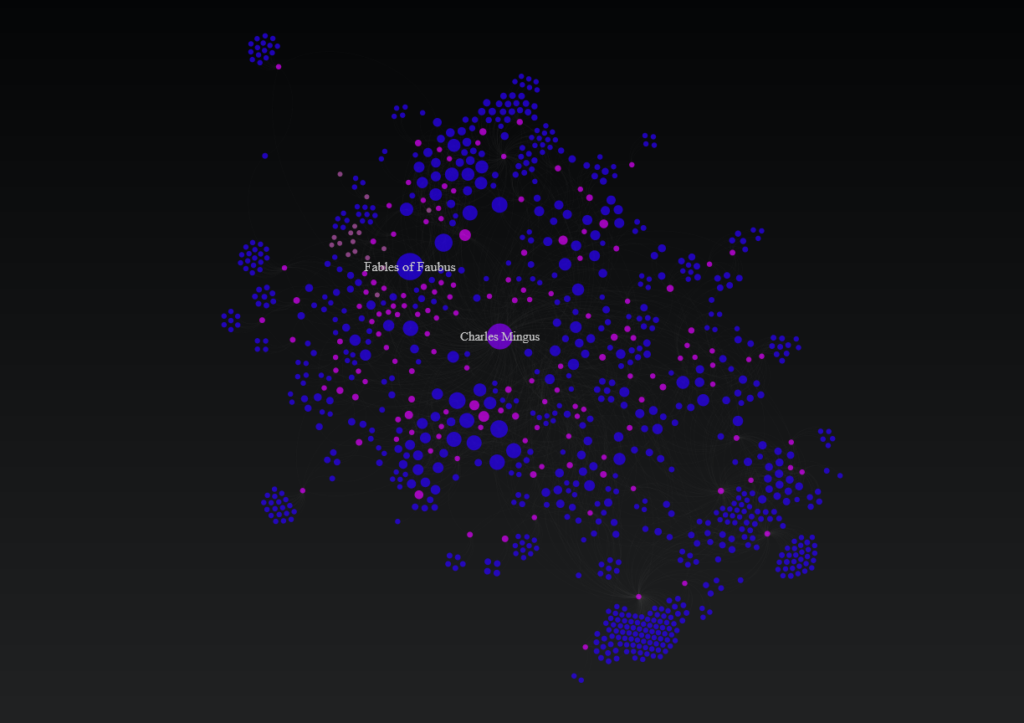
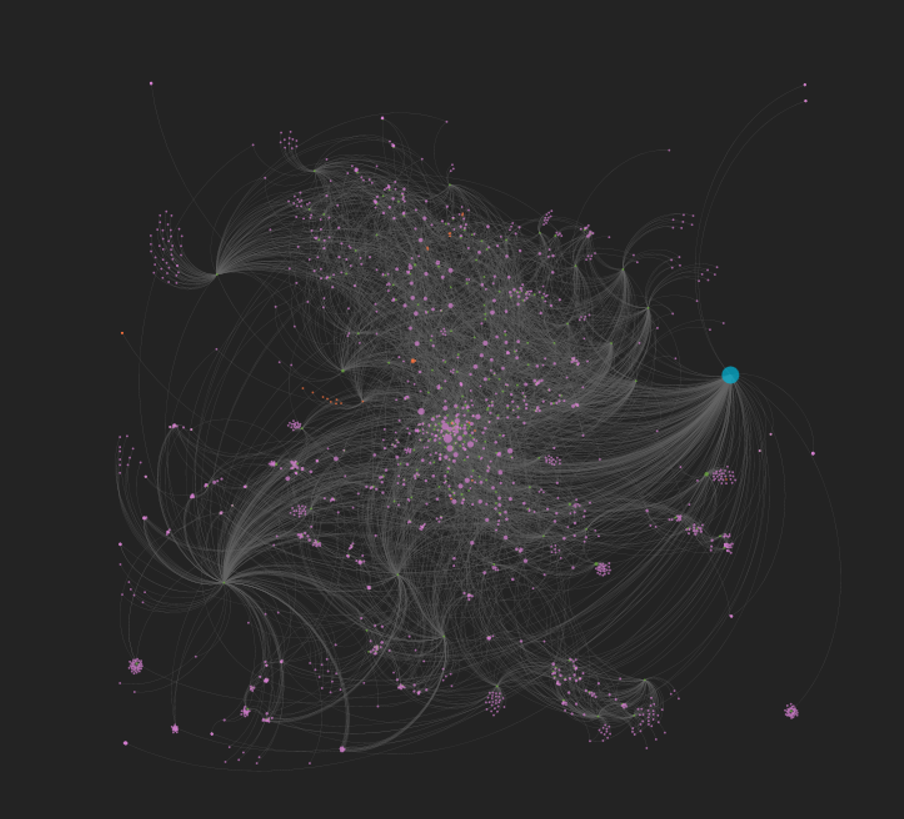
The plan is to get the data refreshed over the next week, and then to start building some interesting networks covering pivotal artists; in the past I did some work presenting networks for Charles Mingus, Miles Davis, and the ECM label.
Mingus:
Miles:

ECM:

Stay tuned for some fresh new work in the coming weeks and months!