Once again I have pulled the core MusicBrainz tables into my local version of PostgreSQL, where I can start exploring all sorts of musical data – recordings, releases, places, artists, and much, much more. The database is large, totaling nearly 17 gigabytes of data across 171 tables, so there is no shortage of potential topics to explore.
One of the areas that intrigues me the most is an exploration of musical genres, created in MusicBrainz for contributors to categorize recordings. While the genres don’t currently tie in to individual recordings or releases in the database, I hope to use them with my own collection of music to create some potentially interesting visualizations. For now, let’s undertake an exploration of the raw data on genres, using the DBeaver database tool.
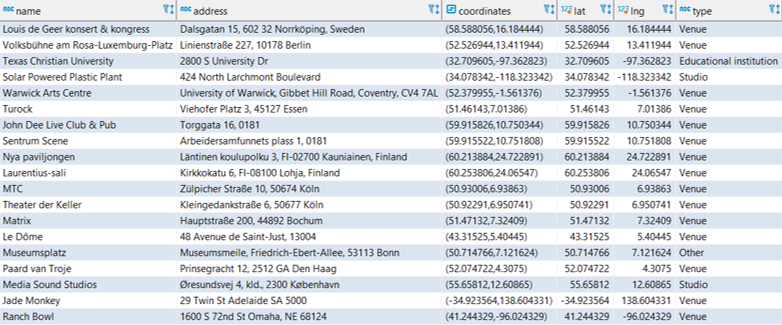
Our first table is simply named genre; let’s look at a screenshot of some of the data:
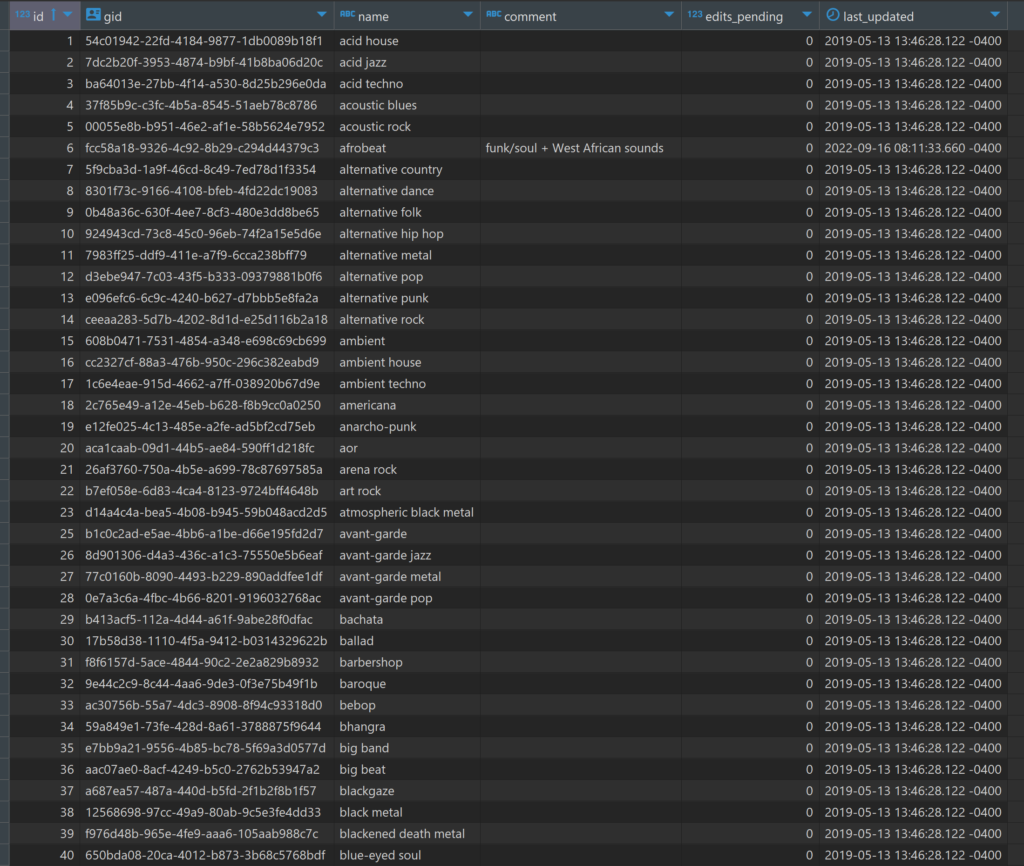
Each genre has a unique id and gid value linked to a distinct genre name such as acid house, arena rock, or bebop. As you can tell, we’re going to a very specific level here, not simple classifications like pop, rock, or jazz. This should make it quite interesting (but not so easy!) when I start tagging my own music collection.
A second table is named genre_alias; here we find some examples where distinct names are rolled up to a single genre id to join to the genre table we just saw. For instance, have a look at some of the entries below:
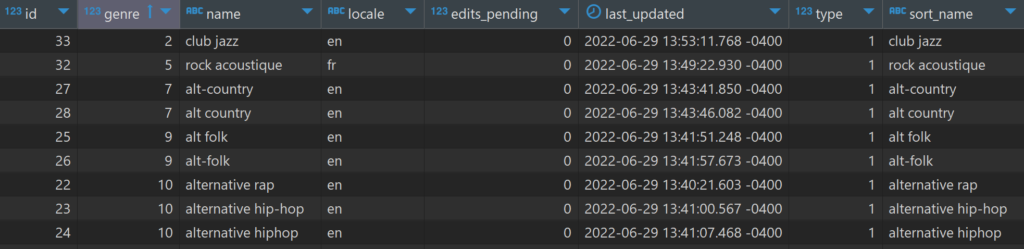
We see multiple rows pointing to a single genre id (the genre column), largely based on alternative spellings or differing punctuation. The last three rows display one such case – alternative rap, alternative hip-hop, and alternative hiphop all have a genre value of 10; in the genre table this classifies all three as alternative hip hop. In other words, these entries are three possible variations on the original alternative hip hop genre; they all represent the same musical genre. In a sense, this is some data cleansing that I won’t need to perform.
A third table is named l_genre_genre; it ties together sub-genres with a higher level ‘umbrella’ genre. Using the alternative hip hop example from above, let’s dive into this table, where we can see the 10 value in the entity1field:

Note the 199 value in the entity0 column; if we refer back to the genre table, here’s what we see:
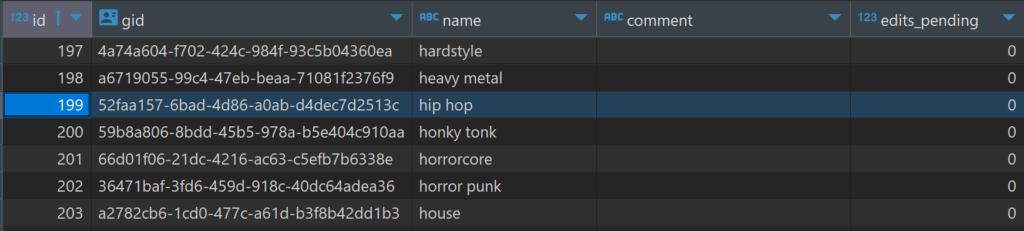
The 199 id value corresponds to hip hop, which contains the alternative hip hop genre, as well as any other sub-genres related to hip hop. So entity0represents the higher level grouping, with entity1 representing the next level down (a sub-genre). In terms of classifying music, we can now use two levels, which may prove useful when it comes to building visualizations.
Is there anything we can visualize at this early stage? How about a very simple sunburst chart? These will become far more interesting when I can tag my own collection with genre info, but for now, here’s a conceptual look using Flourish. You can use the filter or click on a genre to focus the display.
I hope you can see the potential here; ultimately each genre and sub-genre will be sized based on the number of albums (vinyl & CD) in a collection. This will provide a quick visual indication for where someone’s musical preferences lie. There may even be the possibility to take it down to the single recording level, but we’ll have to test that idea.
That’s it for now; looking forward to doing some more fun stuff with the MusicBrainz data. Thanks for reading!