As the initial versions of my JazzGraphs networks are being tested, I thought this would be an appropriate time to walk through the process I use for moving the data from raw database form to the eventual network graph output shared on this site. Mind you, I am still iterating through the data, testing what works best for graph creation, and otherwise seeking to create some memorable output that pays homage to many of the great jazz artists of the last 100 years. Ultimately, the process could change a bit, but it feels like things are pretty stable for the moment. So here goes with a basic outline for the steps currently being taken to create the graphs.
Of course it all starts with the data. Without a good data source, these graphs would be tremendously challenging to create. One could do some web scraping, endless Google searches, or even go old school with trips to the local library. None of these approaches are efficient nor would they yield the amount of data I would like to have for this project. Enter MusicBrainz, a quite remarkable site devoted to building the most comprehensive source of all things musical. Their stated mission is to be:
-
- The ultimate source of music information by allowing anyone to contribute and releasing the data under open licenses.
- The universal lingua franca for music by providing a reliable and unambiguous form of music identification, enabling both people and machines to have meaningful conversations about music.
While the content in any such site is never perfect (think Wikipedia), it nonetheless provides a fantastic starting point for projects such as JazzGraphs.
Fortunately for me (and other SQL coders), the MusicBrainz database is available in a PostgreSQL format, which is very similar to the MySQL databases more familiar to me. So the learning curve has been anything but steep in technical terms. The greater challenge has come in the sheer number of tables and fields in the database, and figuring out which ones are highly populated versus the ones intended for future growth. Another interesting aspect is the multiple spelling variations available for a single song or even an album release. Such are the challenges with public contributions; fortunately they are more than offset by the impressive level of detail available for many artists.
To add some visual perspective, here’s a view of the MusicBrainz schema I am tapping into for the JazzGraphs data:
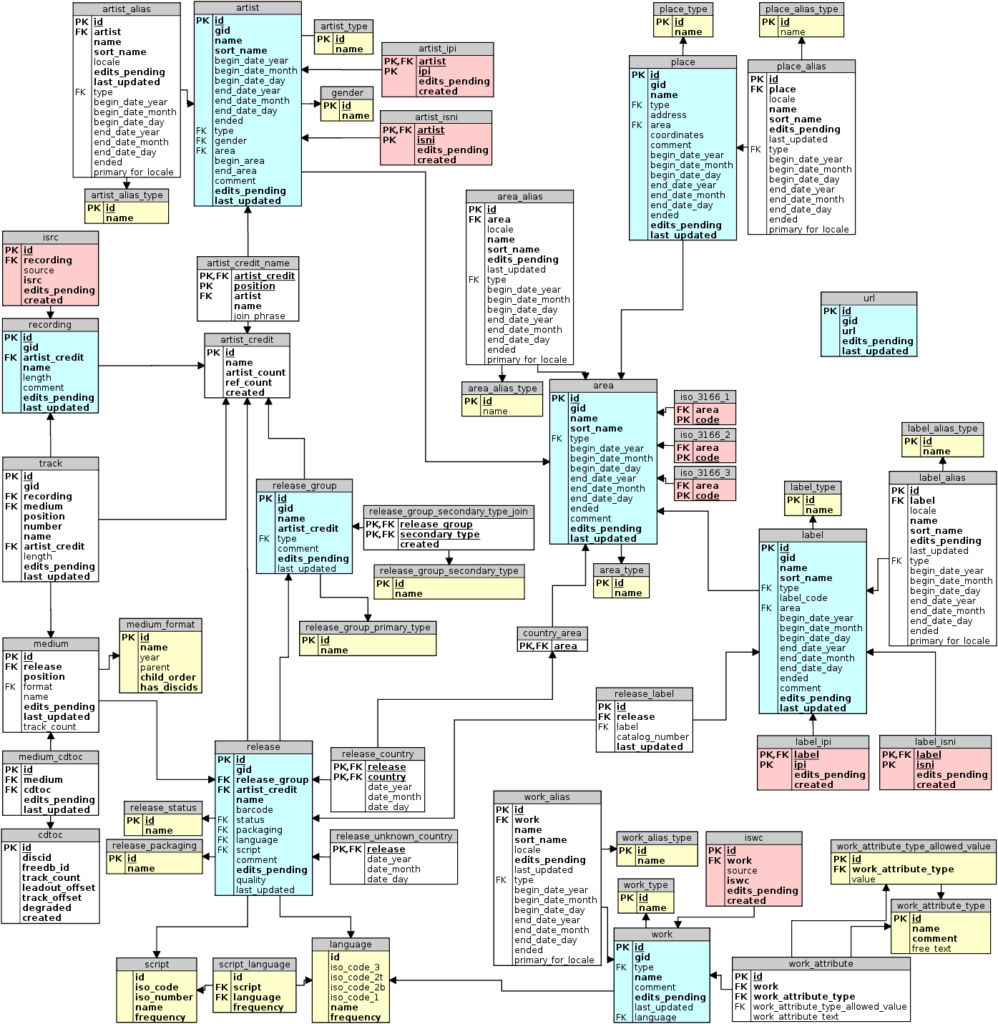
So now you have a basic idea for what the database looks like, how joins are implemented, and how the general naming conventions work. Much of the artist information is found in the upper left of the diagram, with release details in the lower left. Works (songs) can be seen in the lower right quadrant, while the upper right is largely concerned with location and label information. Note that this is but a small subset of the more than 300 tables in the database.
Once the data is available, the challenge is to understand all the relationships within the data, as well as where to find the most robust tables and fields. As I noted earlier, not all tables are populated equally at this point, so it is critical to work within the framework of what’s currently in the database. Fortunately, for a prominent artist such as Miles Davis, we find plenty of data in some of the key tables. This enabled me to begin testing SQL code, and to also envision how I might wish to display the data in a network graph. After a few rounds of testing, I arrived at the conclusion that using a tri-modal approach might be the best approach. In other words, the artist (Miles Davis, in this case) connects directly to specific releases (an album or CD), which in turn connect directly to the songs on the release. What makes this approach appealing is the fact that many songs show up on multiple releases; otherwise, we would wind up with a simple hierarchical (think organization chart) output, and that wouldn’t be much fun 🙂 .
The next step is to create output for use in Gephi. Recall that in most cases, network graphs require both node and edge inputs. What do these represent in our current case? Since nodes are the graphical representation of specific objects or entities, we have three types in this analysis:
-
- The artist (Miles Davis)
- All releases (Kind of Blue, Bitches Brew, etc.)
- All songs (So What, Milestones, etc.)
Each of these elements should have a single node; we can later adjust for frequency by sizing the nodes in our graph. For example, if ‘So What’ shows up on 20 releases, we want to display a single node that connects to each of those releases, and then size the node based on frequency. More on that in a bit. So our initial code will focus on creating these nodes, as shown below, using a UNION query to place all of our nodes in a single result, which can then be exported to a .csv file for Gephi to ingest. Here’s the code:
SELECT a.*
FROM
((SELECT CONCAT(ac.name, ‘ (Artist)’) AS id, ac.name AS name, ac.name AS label, ‘Artist’ AS type, 50 AS size
FROM public.artist_credit ac
WHERE ac.id = 1954)
UNION ALL
(SELECT CONCAT(r.name, ‘ (Release)’) AS id, r.name AS name, r.name AS label, ‘Release’ AS type, COUNT(DISTINCT rl.release) AS size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
WHERE r.artist_credit = 1954
GROUP BY r.name
)
UNION ALL
(SELECT CONCAT(ta.name, ‘ (Song)’) AS id, ta.name AS name, ta.name AS label, ‘Song’ AS type, COUNT(DISTINCT rl.release)
AS Size
FROM public.release r
INNER JOIN public.artist_credit ac
ON r.artist_credit = ac.id
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.medium_format mf
ON m.format = mf.id
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.label l
ON rl.label = l.id
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE r.artist_credit = 1954
GROUP BY ta.name
)) a
As you may have gathered, the ‘1954’ value for the artist_credit corresponds with Miles Davis’ unique id in the database. The beauty of this code is that we need only modify that id in each of the 3 code sections to pull the same type of detail for another artist. So our code is highly reusable. Once our results have been returned, we simply export the results to a .csv format.
Now that the node code has been completed, it’s time to focus on the creation of edges, the connections between nodes. In this case, we want releases to connect only to the artist, and songs to connect only to releases. Once again we’ll use SQL UNION logic to merge results from each section into a single set of results for use in Gephi. Here’s a look at the code for edge creation:
SELECT a.*
FROM
((SELECT CONCAT(ac.name, ‘ (Artist)’) AS source, CONCAT(r.name, ‘ (Release)’) AS Target, ‘Artist’ AS source_type, ‘Release’ AS target_type
FROM public.artist_credit ac
INNER JOIN public.release r
ON ac.id = r.artist_credit
INNER JOIN public.release_label rl
ON r.id = rl.release
WHERE ac.id = 1954)
UNION ALL
(SELECT CONCAT(r.name, ‘ (Release)’) AS Source, CONCAT(ta.name, ‘ (Song)’) AS Target, ‘Release’ AS source_type, ‘Song’ AS target_type
FROM public.release r
INNER JOIN public.release_label rl
ON r.id = rl.release
INNER JOIN public.medium m
ON r.id = m.release
INNER JOIN public.track t
ON m.id = t.medium
INNER JOIN public.track_aggregate ta
ON t.name = ta.name
WHERE r.artist_credit = 1954)) a
GROUP BY a.source, a.target, a.source_type, a.target_type
Pretty simple – in the first section, the artist represents the source node, and all releases become the target nodes (source and target values are essential to Gephi edge creation). The second section adds releases as the source nodes, and songs as target nodes. This will give us the tri-modal network structure I spoke of earlier.
Next comes the fun part (not to say that coding can’t be fun 🙂 ) where we start to use Gephi to create our network. The next post will examine how we pull the data into Gephi and start creating our network. Hope you found this informative and helpful, and thanks for reading!
